
You charge $29/month for a "Pro Plan."
OpenAI charges you $0.03 for every 1k tokens.
In traditional SaaS (like Dropbox), a "Heavy User" costs you maybe $0.50 more in S3 storage than a "Light User." In AI SaaS, a "Heavy User" who runs a loop script on your API can cost you $500 in a single afternoon. If you don't implement Fair Use Limits (FUP), your variable costs (COGS) will eventually exceed your fixed subscription revenue.
🧪 Part 1: The "Naive" Implementation (And why it fails)
Most developers try to fix this by counting requests in a database.
🧠 The Strategy:
"If a user hits 50 requests in an hour, block them."
🐍 The Code (Python + Redis):
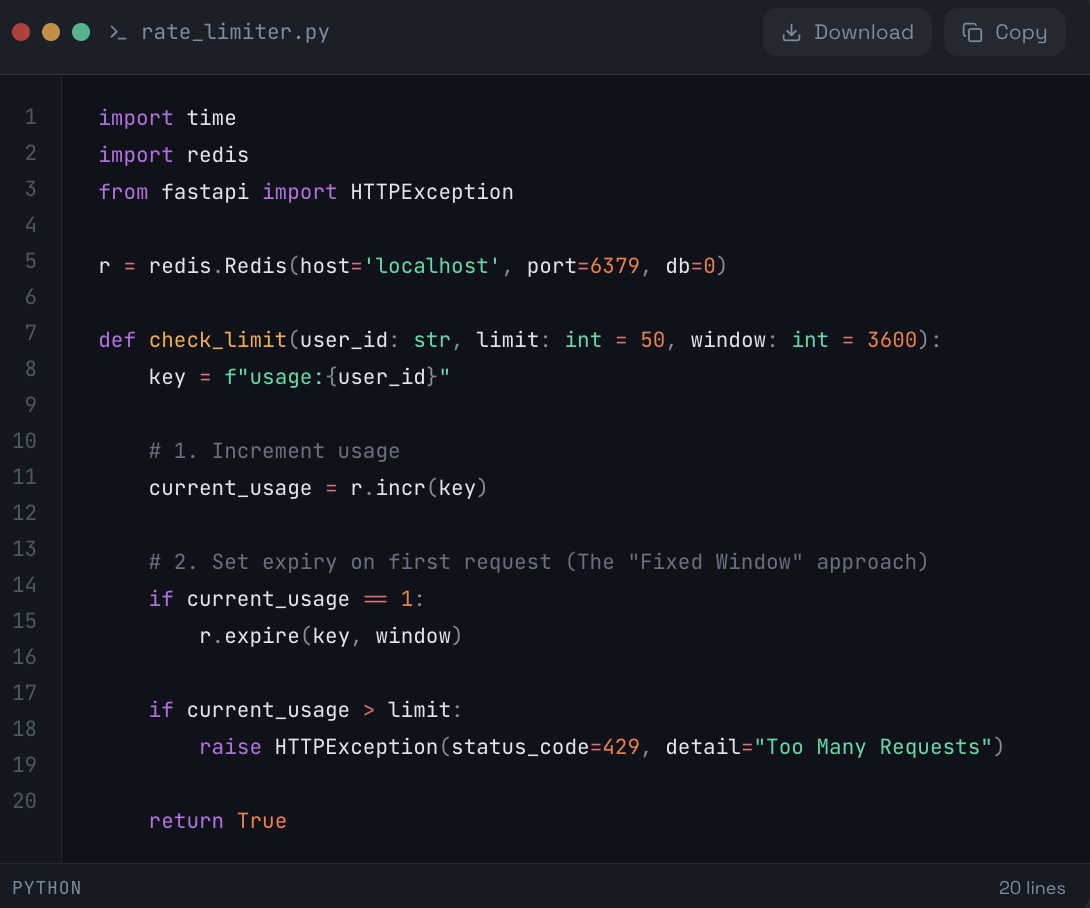
❌ Why this fails:
The "Fixed Window" Spike:
If a user makes 50 requests at 1:59 PM and 50 requests at 2:01 PM, they sent 100 requests in 2 minutes. Your server melts, but your code thinks they are fine.
It ignores Cost:
A request that says "Hi" costs $0.0001.
A request that says "Summarize this 500-page PDF" costs $2.00.
Treating them both as "1 Request" is financial suicide.
⚙️ Part 2: The "Fair Use" Algorithm (Sliding Window + Cost Weighting)
To solve this, we need a Sliding Window (to smooth out bursts) and Weighted Costs (to account for expensive vs. cheap requests).
🧠 The Technical Concept:
We assign a "Weight" to every feature.
- Chat message: 1 point
- Image Gen: 50 points
- PDF Analysis: 100 points
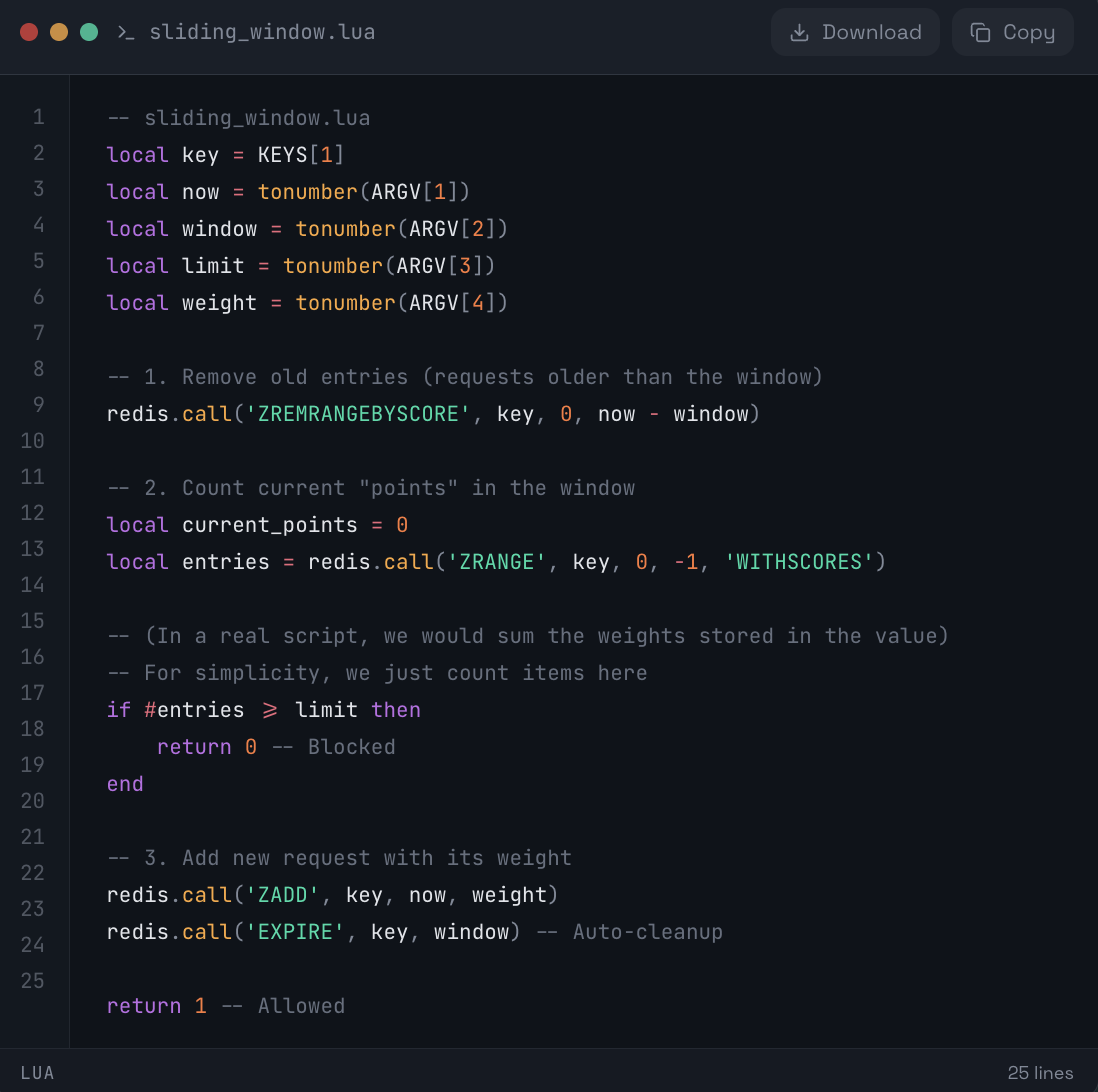
🧠 The Better Code (Lua Script for Atomicity):
We use a Redis Sorted Set (ZSET) to track the timestamp of every request. This creates a perfect "Moving Window."
🧩 Lua
🎛 Part 3: The "Soft Limit" Strategy (UX)
Don't just throw a 429 Error when they hit the limit. That causes churn.
Implement a "Soft Cap" that degrades experience before blocking it.
- 0–80% Usage: Fast Model (gpt-4-turbo), High Priority Queue.
- 80–100% Usage: Standard Model (gpt-3.5-turbo), Standard Queue.
- 100%+ Usage: "You are in the slow lane." (Requests are delayed by 5s or routed to a cheap open-source model like Llama-3).
🌍 Part 4: The Twist (The "Distributed State" Nightmare)
Implementing the Lua script above works great for one server. But what happens when you have:
- 50 Kubernetes Pods scaling up and down?
- 3 Regions (US, EU, Asia)?
- Latency issues syncing Redis across oceans?
If User A hits your US server and User B hits your EU server at the same time, they can double-spend their quota before the databases sync.
In high-frequency trading or massive AI automated agents, this "slippage" can cost you thousands per month.
🧠 The Solution: Aden Global Rate Limiters
Aden solves the distributed state problem by providing a Global, Low-Latency Ledger for AI usage.
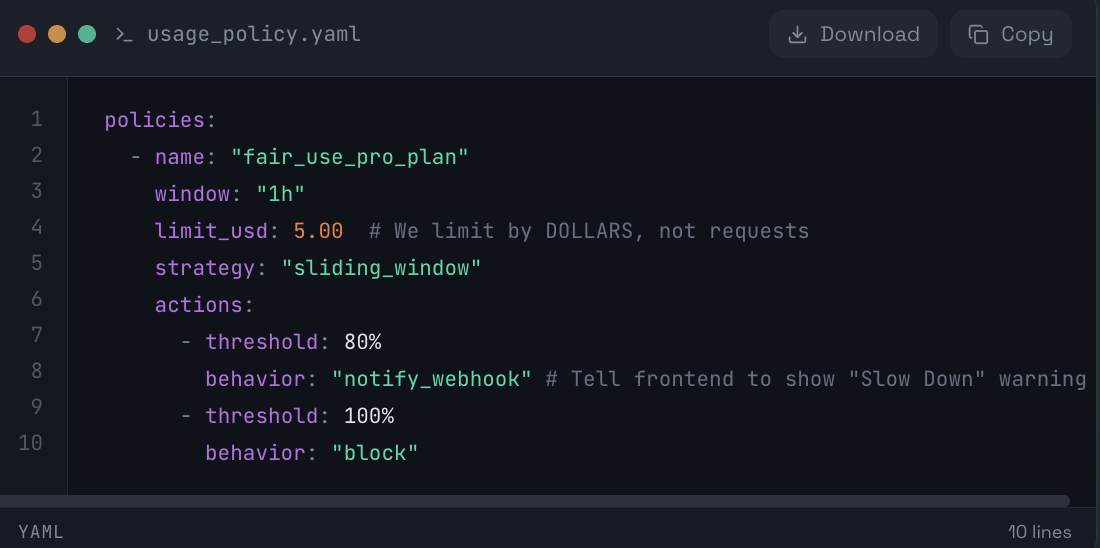
Instead of managing Redis scripts and race conditions, you define a Policy in Aden.
🧾 Aden Configuration:
⚙️ YAML
🐍 The Implementation:
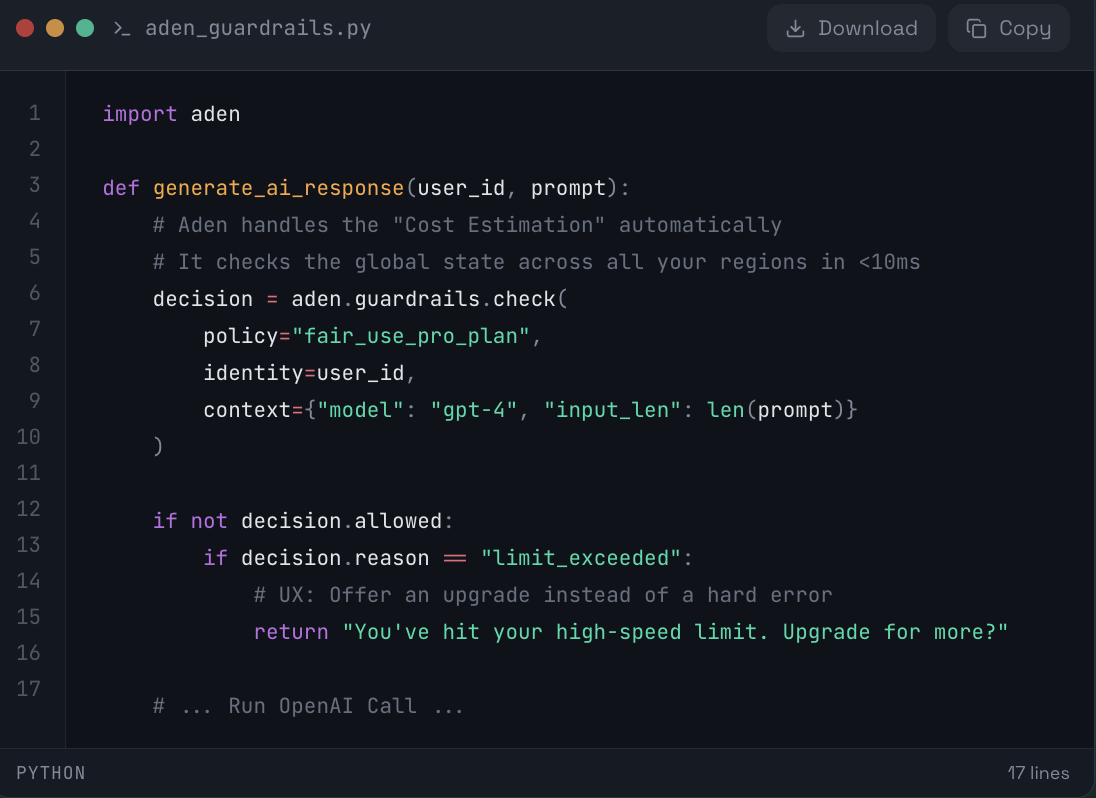
🏆 Why this wins:
- Dollar-Based Limiting: You align your limits with your actual bank account, not arbitrary "request counts."
- Global Sync: Aden prevents the "Double Spend" problem across regions.
- No Ops: You don't have to maintain a high-availability Redis cluster just to count tokens.